



Introduction
Lately I’ve been seeing these new vector databases all over the place, it triggered my curiosity and wanted to see what’s behind all that hype. So, naturally, I turned to Google and did some reading to get a grasp on the topic.
In this article, I'll walk you through some of the basic concepts of vector databases, and we will build an end to end artwork similarity search project using Qdrant Vector database and Streamlit.
Without further ado, let’s dive right in.
Vectors, what are they?
Before delving into vector databases, it's important to grasp the concept of a vector.
A vector is a data structure typically comprised of at least two components: magnitude and direction. However, for simplicity, let's consider it as a list of scalar values, such as [2.7, -1.13, 0.45, 4.87].
But why are they referred to as vectors when they appear to be nothing more than lists of numbers?
Well, the term "vector" is used to emphasize the mathematical and computational aspects of these organized lists of numbers. As we will see, we can perform various calculations with vectors, such as computing dot products, determining distance between vectors to measure similarity, and more.
What are they useful for you might ask?
In practice, data comes in different forms, ranging from structured formats like tabular data to unstructured formats like images, text and sound, and in order to make this data usable by machine learning models, we usually need to extract features, using what’s called feature engineering. However, there are instances when the data exists in high-dimensional spaces, making it incredibly challenging to manually extract meaningful features. This is why we need a way to automatically extract important features.
To solve this challenge, we can use pretrained models. These models can easily extract and transform our data into vectors or vector embeddings while preserving the valuable information, because we don’t just want to convert our data into a list of random numbers, but also conserve key features and characteristics of the data as well.
For example, Word2Vec, BERT ****and GPT are some famous embedding models trained on large labeled text data. They are often used to embed text while preserving the meaning of sentences and capturing whether they convey the same meaning or not.
And for images, models like VGG, ResNet and Inception are often used, they can easily extract key features from images since they are trained on very large datasets.

These are some use cases where vector embeddings come in handy:
Image Search
Audio Search
SImilarity Search
NLP tasks such as sentiment analysis, semantic search..
How can these models accurately transform our data into a vector representation?
The process differs between text and image data.
Text embeddings
Generally, there are two approaches:
- Word-level Embeddings: Models like Word2Vec, GloVe, and FastText calculate word embeddings based on the surrounding words. This allows words with similar meaning to have similar representation and be closer in distance. These models utilize techniques such as skip-gram or continuous bag-of-words (CBOW) to learn vector representations of words that capture their semantic relationships.

source: Google Images
- Contextualized Embeddings: Models like BERT and GPT take contextualized embeddings to one step ahead. They use transformer-based architectures to generate word embeddings that capture not only the word's meaning but also its context within a sentence. These models consider the surrounding words and their order to produce embeddings that represent the word's meaning in different contexts.

source: https://embeddings-explained.lingvis.io/
Image embeddings
If you have ever worked on a computer vision problem or done some image manipulation, you'll know that an image is nothing more than a matrix of numbers where each cell represents the color of a pixel. We can say that this matrix representation of the image is a kind of vector embedding. However, in reality, it's not very practical as it is highly sensitive to basic image transformations such as scaling or cropping, causing the image to lose its important features. That's why we primarily use convolutional neural networks (CNN) for this task.

CNN Architecture (source)
Models like VGG, ResNet, InceptionV3, MobileNet, and EfficientNet are typically based on CNN architectures. These models are trained on large-scale labeled image datasets, and learn to extract visual features from images using convolutional layers and pooling operations.
There is another category of models that combines text and images, called vision-language models. One good example of that would be CLIP (Contrastive Language-Image Pretraining) by OpenAI which is a an open source, multi-modal, zero-shot model, It combines language and image understanding to generate joint embeddings for text and images. The model is trained to associate corresponding pairs of text and image inputs, learning to understand the relationship between them.

source: https://openai.com/research/clip
Vector Database
Now that we have a general idea about vector embeddings, let's move on to discuss vector databases.
Vector databases are specifically designed to efficiently store and manage vector embeddings, enabling fast similarity search and retrieval. These databases employ advanced indexing techniques and data structures that are optimized for handling high-dimensional vector data.
When working with these databases, the process is usually as follows:
Prepare vector embeddings using an embedding model.
The database uses an indexing algorithm that facilitates efficient search operations, such as Locality-sensitive hashing (LSH), Hierarchical Navigable Small World (HNSW), k-d trees or ball trees.
When a vector is inserted into the database, the indexing algorithm assigns it to an appropriate region in the index structure. This process ensures that similar vectors are stored close to each other, enabling faster retrieval during similarity searches.
During a similarity search, a query vector is compared against the vectors stored in the database using similarity metrics such as cosine similarity or Euclidean distance. The indexing structure is traversed to identify the most relevant regions and vectors, significantly reducing the search space and improving search efficiency.
Some of the most used vector databases now are Qdrant, Weaviate, chroma and Pinecone.
You can visit this comprehensive benchmark to learn more about the differences between these vector databases.
Project: Artwork Similarity Search
Now enough talk, let’s actually use these concepts in practice.
Talk is cheap, show me the code - Linus Torvalds
We will create a Streamlit app that enables users to search for similar artworks based on either an uploaded image or a text description. The app will utilize a pretrained deep learning model called CLIP to encode the uploaded image or text description into a vector representation. This vector representation will be compared to a database of artworks using the Qdrant similarity search engine. The app will present the top matching artworks to the user, along with information about the respective artists.
If you are in a rush, here’s the Github repo of the completed project (don’t forget to⭐ 😄)
This is an overview of the project’s architecture.

Project architecture
The process will be as follows:
The user has the choice to either upload an image of a painting, or just write a text description.
The chosen input will be encoded using the CLIP model, which is capable of encoding both images and text due to its multi-modality.
The encoded input will be used to search the Qdrant database for similar vector embeddings using the Qdrant similarity search engine, retrieving the top matching vectors payload.
Using the data from the search result payload, the similar artworks from Google Cloud Storage will be retrieved along with the artists' data.
The results will be displayed back to the user in the Streamlit UI.
The essential libraries needed for this project are:
cloudpickle: For opening pickles files using their URL.kaggle: To download the dataset from kaggle. (can also be done directly from the website's UI).Pillow: For opening images.qdrant_client: Python client for Qdrant vector search engine.sentence_transformers: Python framework for state-of-the-art sentence, text and image embeddings, it provides a wrapper for the OpenAI CLIP model, which is needed for encoding images and text.streamlit: To easily build web UI using Python.toml: File format for configuration files. Needed for secrets management.google-cloud-storage: Python client for Google Cloud Storage, where the artworks data will be stored.
Data Collection
First we’ll need some data containing artworks and their corresponding artists, luckily, there’s this great dataset on Kaggle that provides exactly what we want: A collection of Paintings of the 50 Most Influential Artists of All Time.
Data Preparation
The code for this part can found in data/data_prep.ipynb
- Some artists' names are not encoded correctly, leading to display issues. For example,
Albrecht Durerwas displayed asAlbrecht Düre, which should be fixed to avoid any problems later.
# fixing some issues in folder names
p = os.path.join(IMAGES_DIR,'Albrecht_Durer')
os.rename(os.path.join(IMAGES_DIR, 'Albrecht_Dürer'), p)
for img in os.listdir(p):
os.rename(os.path.join(p, img), os.path.join(p, img.replace('Albrecht_Dürer', 'Albrecht_Durer')))
- Let’s see how many artworks per artist exist in this dataset:
artists = os.listdir(IMAGES_DIR)
pics_per_artist_list = [os.listdir(os.path.join(IMAGES_DIR, artist)) for artist in artists]
artists_artwork_dict = {artist:pics_per_artist for (artist,pics_per_artist) in zip(artists, pics_per_artist_list)}
artworks_count = [len(artists_artwork_dict[artist]) for artist in artists_artwork_dict.keys()]
images_per_artist = {artist:image_count for (artist, image_count) in zip(artists, artworks_count)}
print(images_per_artist)
{'Albrecht_Durer': 328,
'Alfred_Sisley': 259,
'Amedeo_Modigliani': 193,
'Andrei_Rublev': 99,
'Andy_Warhol': 181,
'Camille_Pissarro': 91,
'Caravaggio': 55,
'Claude_Monet': 73,
'Diego_Rivera': 70,
'Diego_Velazquez': 128,
'Edgar_Degas': 702,
'Edouard_Manet': 90,
'Edvard_Munch': 67,
'El_Greco': 87,
'Eugene_Delacroix': 31,
'Francisco_Goya': 291,
'Frida_Kahlo': 120,
'Georges_Seurat': 43,
'Giotto_di_Bondone': 119,
'Gustave_Courbet': 59,
'Gustav_Klimt': 117,
'Henri_de_Toulouse-Lautrec': 81,
'Henri_Matisse': 186,
'Henri_Rousseau': 70,
'Hieronymus_Bosch': 137,
'Jackson_Pollock': 24,
'Jan_van_Eyck': 81,
'Joan_Miro': 102,
'Kazimir_Malevich': 126,
'Leonardo_da_Vinci': 143,
'Marc_Chagall': 239,
'Michelangelo': 49,
'Mikhail_Vrubel': 171,
'Pablo_Picasso': 439,
'Paul_Cezanne': 47,
'Paul_Gauguin': 311,
'Paul_Klee': 188,
'Peter_Paul_Rubens': 141,
'Pierre-Auguste_Renoir': 336,
'Pieter_Bruegel': 134,
'Piet_Mondrian': 84,
'Raphael': 109,
'Rembrandt': 262,
'Rene_Magritte': 194,
'Salvador_Dali': 139,
'Sandro_Botticelli': 164,
'Titian': 255,
'Vasiliy_Kandinskiy': 88,
'Vincent_van_Gogh': 877,
'William_Turner': 66}
For simplicity sake, let’s only keep 20 artworks per artist.
We'll update the artists' bios with more summarized ones.
Instead of keeping all the data in separate columns, we'll organize it into a Python dictionary and pickle it.
# converting this csv to a dict to be used as a payload in our vector search
import csv
csv_filename = 'artwork_data/artists_data.csv'
artists_dict = {}
with open(csv_filename) as f:
reader = csv.DictReader(f)
for row in reader:
artists_dict[row['name']] = {'years': row['years'], 'genre': row['genre'], 'nationality':row['nationality'], 'bio': row['bio'], 'wikipedia': row['wikipedia'], 'paitnings': row['paintings']}
For example artists_dict['Amedeo Modigliani']
{'years': '1884 - 1920',
'genre': 'Expressionism',
'nationality': 'Italian',
'bio': 'Amedeo Modigliani - an Italian painter and sculptor known for his distinctive style of elongated figures, which often have mask-like faces. He was a part of the Parisian art scene in the early 20th century and was influenced by both African art and Italian Renaissance painting. Modigliani died at a young age due to alcohol and drug addiction.',
'wikipedia': 'http://en.wikipedia.org/wiki/Amedeo_Modigliani',
'paitnings': '193'}
After preparing the data, we’ll upload it all to our Google Cloud storage bucket.
For more on how to create Google Cloud Storage buckets, you can follow this tutorial.

Creating a Vector Database
The code for this part can found in qdrant/initialize_db.py
As mentioned earlier, we are going to use Qdrant Vector Database. The good thing is that it offers a managed cloud solution that comes with a free forever 1GB cluster, and no credit card is required 🥳
Database Initialization
The Initialize class is responsible for handling the Qdrant database operations.
The __init__ method is responsible for creating instances of the Qdrant client (using credentials from https://cloud.qdrant.io/), and a clip-ViT-B-32 encoder.
The encoder is instantiated using the SentenceTransformer library, and the specific encoder name, clip-ViT-B-32, is retrieved from a .toml configuration file (more about this later).
def __init__(self, qdrant_url, qdrant_key, encoder_name):
self.qdrant_client = QdrantClient(
url=qdrant_url,
api_key=qdrant_key,
)
self.encoder = SentenceTransformer(encoder_name)
Creating the Collection
create_collection creates a Qdrant Collection with a vector size of 512, and COSINE as a distance metric to measure similarity between vectors.
def create_collection(self, collection_name):
self.qdrant_client.recreate_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=512, distance=Distance.COSINE),
)
When the collection is created, we’ll need to insert some data into it.
Adding data to the collection
Each Point object takes an id , vector data, and a payload.
The upsert_data method is responsible for adding data to our collection. It upserts a list of points, which is generated from a list comprehension that loops over a folder of images. For each image, it encodes it into a vector embedding using the CLIP model, and adds a payload to it. The payload includes the artist name (inferred from the image name) and the image name, which will be useful later to retrieve the image from Google Cloud Storage if it matches the user's input.
def upsert_data(self, collection_name):
self.qdrant_client.upsert(
collection_name=collection_name,
wait=True,
points=[
# Generate a PointStruct with an id, vector and metadata for each image in the IMAGES_DIR
PointStruct(
id=id,
vector=self.encoder.encode(
Image.open(os.path.join(IMAGES_DIR, img))
).tolist(),
payload={
"artist": " ".join(
img.split("_")[:-1]
), # Extract artist name from image file name
"image_name": img, # Store image file name
},
)
for id, img in tqdm(enumerate(os.listdir(IMAGES_DIR)))
],
)
Vector Search
Now we need a way to search this data.
The function bellow takes two parameters, query and k.
The query, as mentioned before, can either be a picture or some text. It will be encoded using the CLIP model provided by the SentenceTransformer library.
The k represents the number of similar artworks to retrieve from the search.
def search(self, query, k):
"""
Performs a search on the Qdrant collection using the encoded query vector and returns a list of hit payloads.
:param query: The query that can be either a text or an image to encode and search for in the collection.
:param k: The number of hits to return from the search.
:return: A list of hit payloads containing information about the images associated with the hits.
"""
hits = self.qdrant_client.search(
collection_name=self.collection_name,
query_vector=self.encoder.encode(query).tolist(),
limit=k
) # search the Qdrant collection using the encoded query vector and return the top k hits
for hit in hits:
print(hit.payload, "score:", hit.score) # print the payload and score for each hit to the console
return [hit.payload for hit in hits] # return a list of hit payloads containing information about the images
Secrets management
Before going further, let’s talk about secrets management.
Secrets management refers to the approach you take to protect configuration variables, passwords, API keys, tokens and so on.
It is crucial to ensure that these sensitive variables are not directly included in the source code. Even if the code is meant to be private, it is essential to protect these sensitive values from unauthorized access.
One common approach is to utilize a separate file dedicated to storing these secrets. This file is typically excluded from version control by adding it to the .gitignore file. By doing so, it prevents the unintended exposure of these secrets during the code's development and deployment processes.
And since we are planning to deploy the app to Streamlit Cloud, their platform is more compatible with the TOML format, which we are going to use. Here is what the .toml file of this project looks like.
I removed the value from some attributes for obvious reasons.
title = "Secrets required to run the app"
[Kaggle]
KAGGLE_USERNAME = ""
KAGGLE_KEY = ""
[Database]
EMBEDDER_NAME = "clip-ViT-B-32"
COLLECTION_NAME = "artwork"
QDRANT_URL = ""
QDRANT_KEY = ""
[gcp_service_account]
type = ""
project_id = ""
private_key_id = ""
private_key = ""
client_email = ""
client_id = ""
auth_uri = ""
token_uri = ""
auth_provider_x509_cert_url = ""
client_x509_cert_url = ""
We can then read this file using st.secrets from the Streamlit library.
import os
import streamlit as st
CODE_DIR = os.path.dirname(__file__)
ROOT_DIR = os.path.dirname(CODE_DIR)
DATA_DIR = os.path.join(ROOT_DIR, 'data')
IMAGES_DIR = os.path.join(CODE_DIR ,'data', 'artwork_data','images')
KAGGLE_USERNAME = st.secrets['Kaggle']['KAGGLE_USERNAME']
KAGGLE_KEY = st.secrets['Kaggle']['KAGGLE_KEY']
COLLECTION_NAME = st.secrets['Database']['COLLECTION_NAME']
EMBEDDER = st.secrets['Database']['EMBEDDER_NAME']
QDRANT_URL = st.secrets['Database']['QDRANT_URL']
QDRANT_KEY = st.secrets['Database']['QDRANT_KEY']
GCP_CREDS = st.secrets["gcp_service_account"]
For more on secrets management in Streamlit, you can visit their docs.
Google Cloud Storage
The code for this part can be found in data/from_gcp_bucket.py
We need some functions to retrieve data from the google cloud storage buckets.
We’ll create a GCP class, and its __init__ method initializes the object with the given bucket name and path prefix. The class takes care of authenticating the user using the provided GCP credentials and sets up a storage client to interact with the GCP services.
def __init__(self, bucket_name="artwork-images-streamlit", path_prefix="artwork_data/"):
self.credentials = service_account.Credentials.from_service_account_info(
GCP_CREDS
)
self.storage_client = storage.Client(credentials=self.credentials)
self.bucket_name = bucket_name
self.bucket = self.storage_client.bucket(self.bucket_name)
self.path_prefix = path_prefix
The method below returns an image url given it’s name:
def get_image_url(self, image_name, expire_in=datetime.today() + timedelta(1)):
image_path = self.path_prefix + "images/" + \
'_'.join(image_name.split('_')[:-1]) + "/" + image_name
url = self.bucket.blob(image_path).generate_signed_url(expire_in)
return url
The next method returns the artists data. (That python dictionary we pickled in the Data Prep section)
def get_artists_data(self, filename="artists_data.pkl", expire_in=datetime.today() + timedelta(1)):
file_path = self.path_prefix + filename
url = self.bucket.blob(file_path).generate_signed_url(expire_in)
data = cp.load(urlopen(url))
return data
And lastly, we’ll need a method responsible of returning artworks of a given artist name.
def get_artist_artwork(self, artist, n, expire_in=datetime.today() + timedelta(1)):
file_path_prefix = self.path_prefix + "images/" + artist.replace(' ', '_')
result = self.storage_client.list_blobs(self.bucket_name, prefix=file_path_prefix)
url_list = []
for image_path in itertools.islice(result, n):
url_list.append(self.bucket.blob(image_path.name).generate_signed_url(expire_in))
return url_list
Streamlit UI
The code for this part can be found in app.py
Streamlit makes creating web apps using python extremely easy. It provides ready to use components such as buttons, text inputs and much more.
After importing the necessary libraries and modules, we define the method responsible for creating an instance of the [VectorSearch](https://github.com/Otman404/artwork-similarity-search/blob/master/qdrant/vector_searcher.py) class, and since this class requires instantiating the SentenceTransformer class with the CLIP model which should be downloaded the first time, we need to add caching to the method using [@st.cache_resource](https://docs.streamlit.io/library/api-reference/performance/st.cache_resource) decorator provided by the Streamlit library. This decorator prevents the object to be instantiated each time the app reloads, therefore downloading the CLIP model multiple times, which can be very demanding and causes the app to crash.
@st.cache_resource(show_spinner=False)
def load_search_object():
return VectorSearch(encoder_name=EMBEDDER, qdrant_url=QDRANT_URL,
qdrant_key=QDRANT_KEY, collection_name=COLLECTION_NAME)
We need to allow the user to choose the input method using the st.selectbox component, and then displaying either a file upload (st.file_uploader) or text input (st.text_input) based on that choice.
search_option = st.selectbox(
'How would you like to search for similar artworks?',
('Image search', 'Text search'))
image_bytes = None
artwork_desc = ""
if search_option == 'Image search':
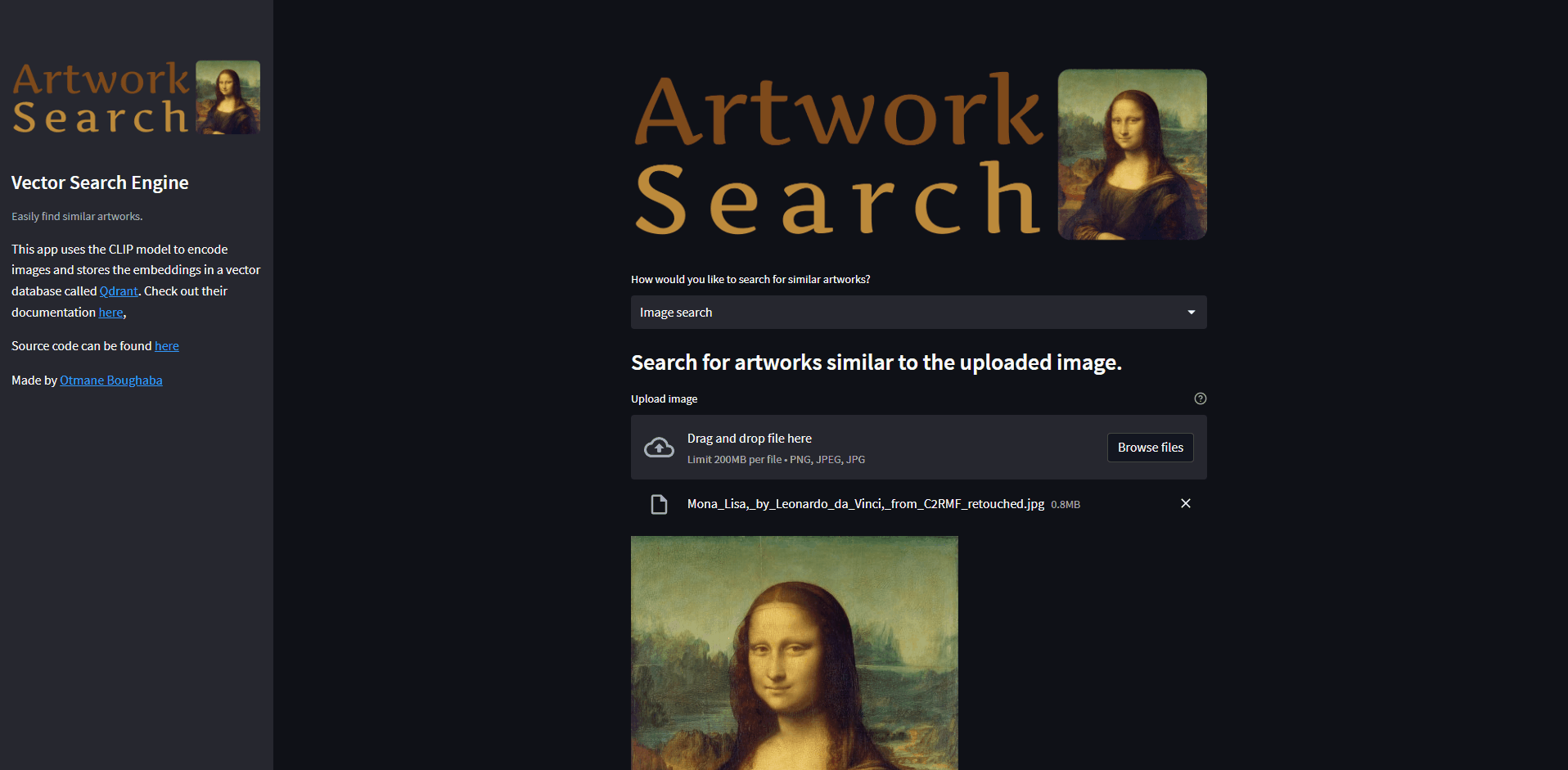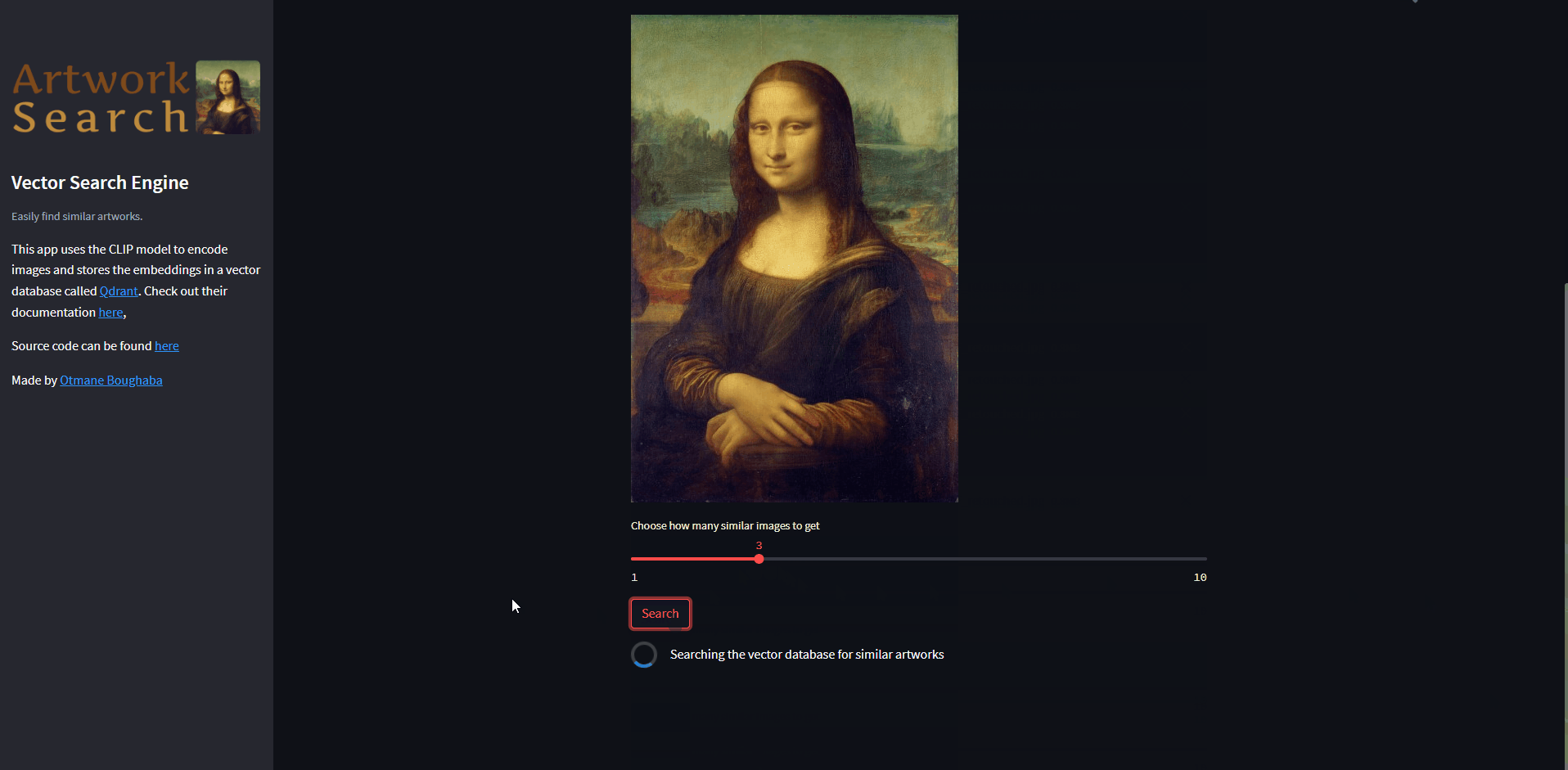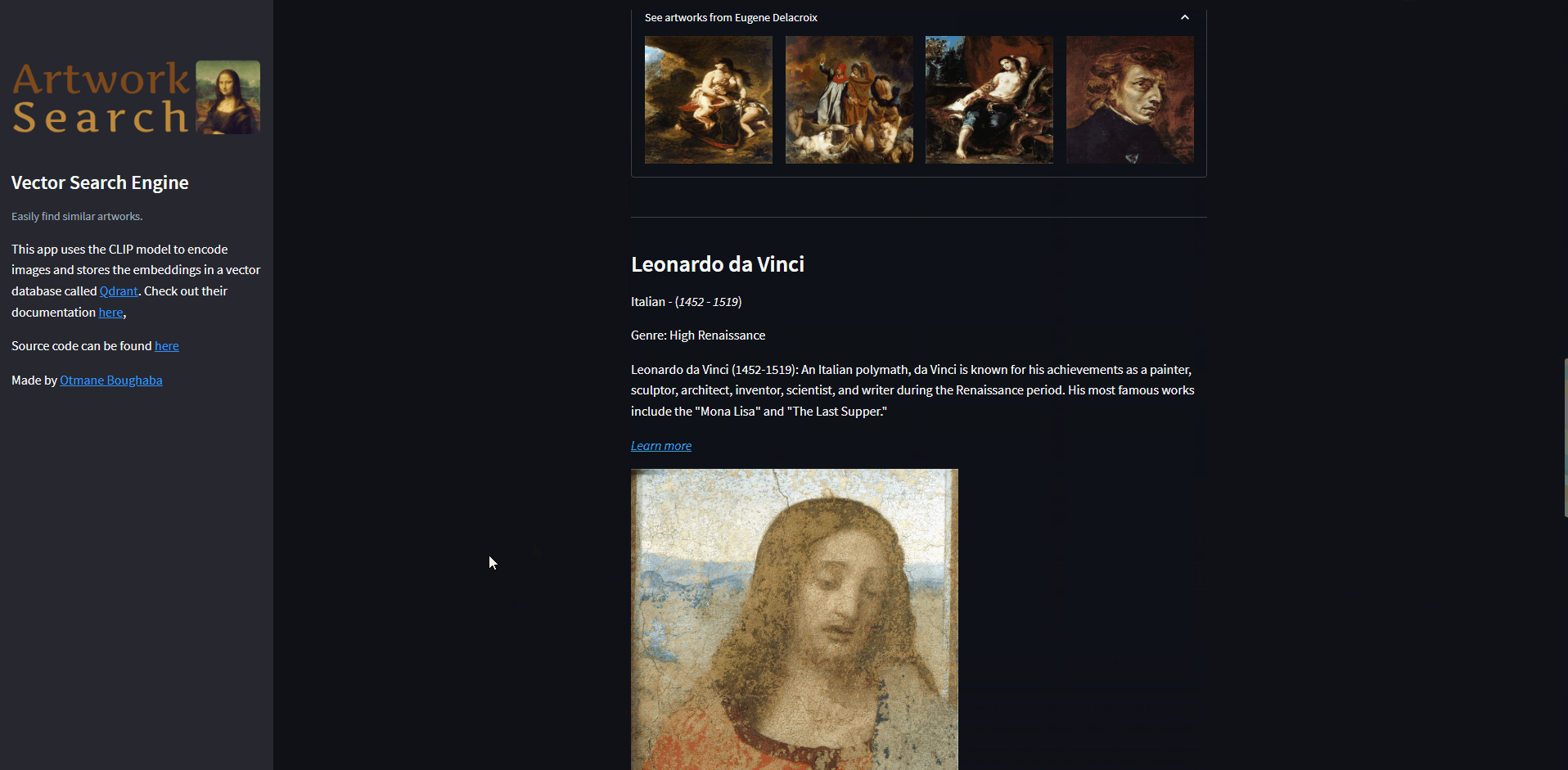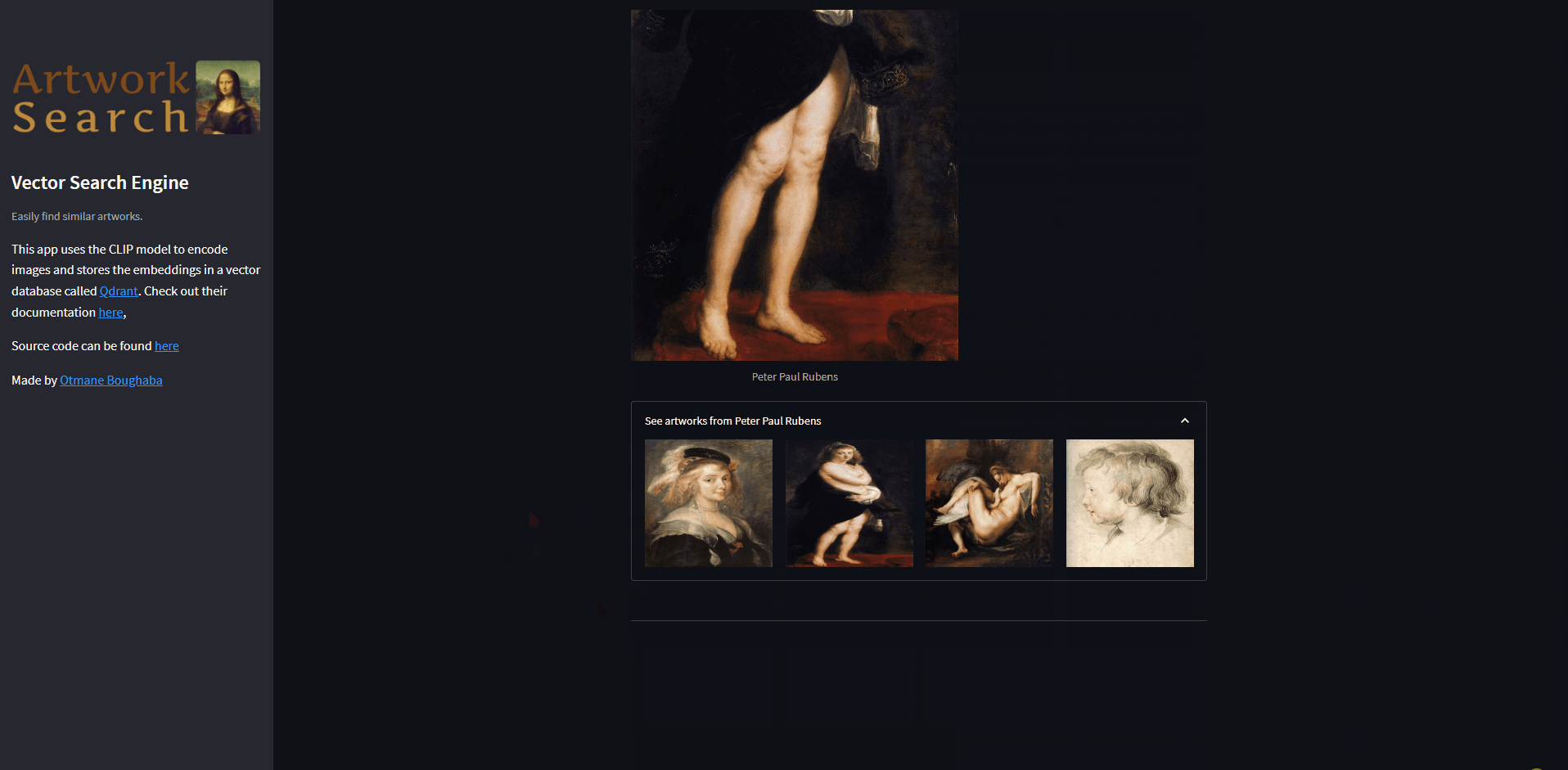
st.markdown('### Search for artworks similar to the uploaded image.')
uploaded_file = st.file_uploader("Upload image", type=[
"png", "jpeg", "jpg"], accept_multiple_files=False, key=None, help="upload image")
if uploaded_file:
# To read file as bytes
image_bytes = uploaded_file.getvalue()
st.image(image_bytes, width=400)
else:
artwork_desc = st.text_input("Describe the artwork")
Now that we have the user’s input, let’s get artists data from google cloud storage, then get the k variable (how many search results to return) from the user using the st.slider component.
When the user clicks on the submit button, we call the [search](https://github.com/Otman404/artwork-similarity-search/blob/4153c7113e417731e20921cebaed757c232b01ed/qdrant/vector_searcher.py#L26C12-L26C12) method from the VectorSearch class, and then we display the results along with some information about their artists.
if image_bytes or artwork_desc:
artists_data = gcp.get_artists_data()
k = st.slider(label='Choose how many similar images to get',
min_value=1, max_value=10, step=1, value=3)
if st.button('Search'):
if not image_bytes and not artwork_desc:
st.write("error")
elif image_bytes:
with st.spinner('Searching the vector database for similar artworks'):
search_result = vectorsearch.search(
Image.open(io.BytesIO(image_bytes)), k)
elif artwork_desc:
with st.spinner("Searching for atwork that matches your description..."):
search_result = vectorsearch.search(artwork_desc, k)
artists_data = gcp.get_artists_data()
st.title("Image search result")
for id, r in enumerate(search_result):
st.subheader(f"{r['artist']}")
st.markdown(
f"{artists_data[r['artist']]['nationality']} - (*{artists_data[r['artist']]['years']}*)")
st.markdown(f"Genre: {artists_data[r['artist']]['genre']}")
st.write(artists_data[r['artist']]['bio'])
st.markdown(
f"[*Learn more*]({artists_data[r['artist']]['wikipedia']})")
st.image(gcp.get_image_url(
r['image_name']), caption=r['artist'], width=400)
with st.expander(f"See artworks from {r['artist']}"):
c1, c2, c3, c4 = st.columns(4)
for img_url, c in zip(gcp.get_artist_artwork(r['artist'] ,4), [c1,c2,c3,c4]):
r = requests.get(img_url)
image = Image.open(BytesIO(r.content)).resize((400,400), Image.LANCZOS)
c.image(image)
st.divider()
Deployment
That’s it! We have all the required components to get our project up and running.
All that’s left to do now it to deploy it on streamlit cloud
On https://share.streamlit.io/deploy, we specify our github repository, the branch, and the main app file, in our case it’s app.py.

Before clicking on the Deploy method, let’s go to the advanced settings to add the secrets (the content in our secrets.toml file)

Click Save, then Deploy.
Now let’s visit the deployment url and test our app 🚀
Demo
With image input
With text input

Looks good! 😀
Conclusion
Vector databases open the door to endless possibilities with their powerful vector search, especially with the rise of large language models (LLMs) such as GPT-3, PaLM, LLaMA, and others, the need for such databases increases drastically, as they can be used as a memory engine for the model or to provide access to additional resources and documents for searching.
I've enjoyed exploring Qdrant while building this artwork search engine. In this article, we have covered all the steps, from data acquisition to app deployment.
I hope this comprehensive breakdown has provided you with a clear understanding of the concept behind vector databases and has inspired you to start your own projects.
Additional Resources
Embedding projector - visualization of high-dimensional data